The 5 Pillars of Agentic AI: From Prompting Models to Engineering Systems
Every AI agent demo is flawless — and then it dies in production. The gap between the demo and the disaster is the five things around the model: memory, state, orchestration, governance, and evaluation. The prompt era is over. This is the engineering era.
Every AI agent demo is flawless. That’s the problem.
It remembers your name, chains three tools, writes the code, nails the reply — and you think we’re basically there. Then you ship it. By Tuesday it’s forgotten you exist, it runs the same task three different ways, it force-pushed to main at 3am, and nobody can tell you whether it actually worked.
Here’s the part nobody says out loud: the demo and the disaster are the same model. The difference is entirely in what you build around it — and two years of “prompt engineering” taught us almost nothing about any of it.
That difference has five parts. Every agent system that survives contact with real work has them; every one that collapses is missing one or two. Here they are on one slide, then one at a time.
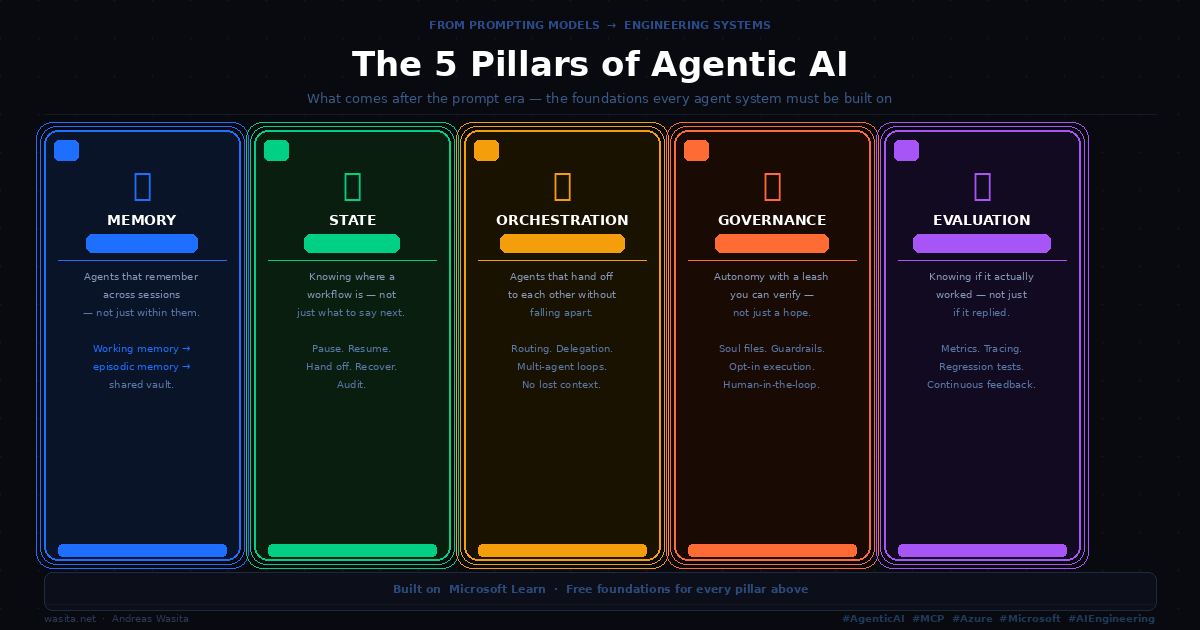
The whole shift fits in one line: a prompt produces a reply; a system remembers, knows where it is, hands work off, stays on a leash, and proves it worked. Those five verbs are the five pillars. Miss one and you’re back to the demo that dies on Tuesday.
1. Memory — remembering across sessions, not just within them
A model has a context window. That’s not memory — it’s short-term attention that evaporates the moment the session ends. An agent with no memory re-meets you every morning, re-learns every lesson, re-makes every mistake.
An agent without memory is a goldfish with an API key.
Real memory has tiers, and the distinction is the whole design:
- Working memory — what’s relevant right now, in-context, for the task at hand.
- Episodic memory — what happened before: past tasks, decisions, the bug you already fixed once.
- Shared memory — a durable store every agent and runtime reads from and writes to, so a lesson one learns is available to all.
Skip this and the failure is expensive and quiet: agents that dazzle in a demo and turn amnesiac in production. Where memory lives — in-context versus a vault every machine can reach — is a design decision, not an afterthought. Get it wrong and your agents are articulate strangers forever.
Go deeper → Part 2: Memory — what MemoryBear and Microsoft Foundry teach us about building a real memory pipeline (extract, consolidate, retrieve) and the underrated art of forgetting.
2. State — knowing where the work is, not just what to say next
Memory is what an agent knows. State is where the work is. Conflating them is why so many agent “workflows” are really one long, fragile turn that dies the instant anything interrupts it.
A system with real state can answer: what step are we on? What’s done, what’s blocked, what’s waiting on a human? And crucially it can pause, resume, hand off, recover, and audit — because the state lives outside any single agent’s head, in something durable.
That’s why I run my agents on an issue-backed board, not a chat loop. Every unit of work is a tracked item with an explicit disposition — done, in-review, blocked, in-progress — and recurring work materialises into auditable tasks instead of vanishing into a transcript.
When state is a first-class object, “the laptop closed mid-run” is a resumable event. When it isn’t, every interruption is a restart.
3. Orchestration — agents that hand off without falling apart
One agent is a tool. Several agents that route work to each other, delegate sub-tasks, and run multi-agent loops without dropping context at every boundary — that’s a system. Orchestration is what turns a pile of capable agents into a workforce.
The hard part was never spawning agents; it’s the handoff. Context lost at the seam is where multi-agent systems quietly rot — the second agent doesn’t know what the first decided, so it redoes it or contradicts it. Good orchestration is routing with intent, delegating to child tasks instead of polling, and keeping the why flowing across every boundary.
It also forces a real decision: how much machinery sits between an agent and its model — a bare local runtime, a kernel that wraps it, or a gateway in front of the whole thing. I mapped that trade-off in detail: every layer buys coordination and charges you in fragility, and the right answer is the lowest layer that does what you actually need.
4. Governance — autonomy with a leash you can verify
The pillar everyone wants to skip and nobody can afford to. Autonomy is the entire point of an agent — and unbounded autonomy is exactly how you wake up to that force-pushed main, a leaked secret, or a four-figure bill. Governance is autonomy with a leash you can verify — not one you hope is holding.
In practice it’s a stack of small, boring controls that compound:
- Stable identity — soul files so a disposable worker has a durable character and limits.
- Guardrails — what an agent may touch, and the trip-wires it must obey.
- Opt-in execution — nothing consequential runs until you assign it.
- Human-in-the-loop — a verifiable checkpoint where it matters, not a rubber stamp.
A leash you can’t verify is just a story you tell yourself about a system you don’t actually control.
Your agents aren’t under-capable, they’re under-governed, and the fix is governing them at scale — to the point of making the pipeline mandatory so discipline isn’t optional.
Go deeper → Part 1: Governance — the four concrete controls (opt-in execution, a verifiable leash, soul files, live guardrails) that turn this pillar from a slogan into something you can inspect.
5. Evaluation — knowing if it actually worked, not just if it replied
The last pillar is the one that separates engineering from theatre. A reply is not a result. An agent that confidently produces the wrong answer, fast, is worse than no agent — and you cannot tell which one you have without evaluation.
That means metrics on outcomes (not just “did it respond”), tracing so you can see why it did what it did, regression tests so yesterday’s fix doesn’t silently break tomorrow, and a feedback loop that turns failures into rules. Evaluation is what makes an agent system improvable instead of merely impressive.
The most useful version I’ve found is teaching agents to learn from losing — treating a failed run as a signal to refine, not an embarrassment to bury.
Without an evaluation loop you don’t have a system that gets better. You have a slot machine that occasionally pays out.
The whole point: each pillar is a thing you build, not a thing you prompt
Line the five up and the shape is undeniable. Memory so it remembers. State so it knows where the work is. Orchestration so the pieces cooperate. Governance so autonomy stays on a verifiable leash. Evaluation so you know it worked. Not one of them is a prompt. Every one is a system you design, build, and operate.
That’s the entire shift the slide is pointing at — from prompting models to engineering systems. The model is the easy part now; it’s a commodity you call. The durable advantage is the five pillars around it.
Pick any agent project that wowed you in a demo and quietly died in production, and I’ll tell you which pillar it skipped.
So start with the one you’re weakest on. For most people that’s evaluation — because it’s the only pillar that tells you the truth about the other four.